 발전기금
발전기금



-

- [학생실적] 석사과정 이윤정, SCIE 논문지(MDPI Sensors/Q2) 게재
- 석사과정 이윤정 학생(지도교수 : 정종필)의 연구(LSTM-Autoencoder Based Anomaly Detection Using Vibration Data of Wind Turbines)가 MDPI Sensors(Impact Factor: 3.9 (2022); 5-Year Impact Factor: 4.1 (2022))에 게재됐다. https://www.mdpi.com/1424-8220/24/9/2833 or https://doi.org/10.3390/s24092833 논문요약 - The problem of energy depletion has brought wind energy under consideration to replace oil- or chemical-based energy. However, the breakdown of wind turbines is a major concern. Accordingly, unsupervised learning was performed using the vibration signal of a wind power generator to achieve an outlier detection performance of 97%. We analyzed the vibration data through wavelet packet conversion and identified a specific frequency band that showed a large difference between the normal and abnormal data. To emphasize these specific frequency bands, high-pass filters were applied to maximize the difference. Subsequently, the dimensions of the data were reduced through principal component analysis, giving unique characteristics to the data preprocessing process. Normal data collected from a wind farm located in northern Sweden was first preprocessed, and a long short-term memory (LSTM) autoencoder, and outlier detection was performed. The LSTM Autoencoder is a model specialized for time-series data that learns the patterns of normal data and detects other data as outliers. Therefore, we propose a method for outlier detection through data preprocessing and unsupervised learning, utilizing the vibration signals from wind generators. This will facilitate the quick and accurate detection of wind power generator failures and provide alternatives to the problem of energy depletion.
-
- 작성일 2024-04-29
- 조회수 225
-
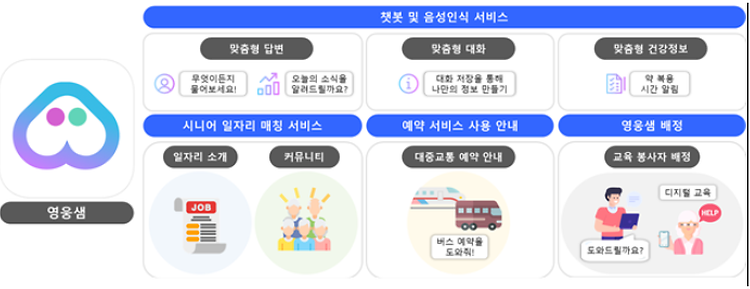
- [학생실적] 2024 SIS 창업동아리 선발 - 스마트팩토리융합학과 연구실
- - 동아리 명 : 동글 ‘동글’은 스마트팩토리융합학과 연구실 학생들의 모임으로 사회 문제를 해결해나가는 공공 서비스 개발을 위해 모인 창업 동아리입니다. 공학 기술을 사회적 가치 창출의 수단으로 활용하여 사회에 선한 영향력을 전파하는 것을 비전으로 합니다. - 창업아이템 명 : 영웅샘 영웅샘’은 시니어들의 디지털 리터러시를 극복하기 위한 도움을 주는 시니어 맞춤형 어플리케이션입니다. 114 서비스처럼 언제 어디서나 도움이 필요한 시니어들을 도와줄 수 있습니다. 기존 어플리케이션과 차별되는‘영웅샘’의 핵심 기능은 음성인식(TTS / STT)기능을 활용한 AI 챗봇, 음성인식 서비스 등 사용자에게 맞춤형으로 정보를 제공하는 것입니다. 또한, 소일거리가 필요한 시니어에게 일자리 매칭 서비스와 커뮤니티를 제공해주고, 예약이 필요한 대중교통을 간편하게 예약할 수 있도록 안내해주기, 영웅샘(디지털 리터러시 교육 봉사자) 배정을 통해 도움이 필요한 즉시, 도움을 주는 기능을 제공합니다. - 팀장 : 문예은, 팀원 : 이윤정, 안지수, 김남지, 이대희 이후, 창업유망팀 예비트랙 300+, AI 스타트업 창업경진대회 참여 등 적극적으로 활동을 이어갈 계획입니다.
-
- 작성일 2024-04-22
- 조회수 417
-

- [교수동정] 습관 분석해 맞춤정보 제공한다 - 스마트팩토리융합학과 박정수 교수
- 박정수 성균관대 스마트팩토리융합학과 겸임교수 사람들의 습관까지 파악해 특정 행동을 예측하고 유도할 수 있는 ‘행동인터넷(IoB: Internet of Behaviors)’이 떠오르고 있다. 행동인터넷은 ‘사물인터넷(IoT: Internet of Thing)’에서 파생된 신조어다. 사물인터넷은 사물에 센서를 설치하여 사용자의 음성이나 행동 등을 분석한다. AI 로봇, AI 공기청정기 등을 예로 들 수 있다. 이에 비해 행동인터넷은 센서가 아닌 사람의 행동 패턴을 분석해 디지털화하는 것을 뜻한다. 사람이 어떤 사이트 또는 어떤 매장을 주로 이용하고 어떤 상품을 구매했는지, 최근에 SNS에서 즐겨보는 상품은 어떤 것인지 등의 정보를 수집하고 분석해 그 데이터를 기반으로 최적의 선택지를 추천해 준다. 예를 들어, 사용자가 인터넷에서 자동차에 관련된 상품들을 주로 검색하고 구매했다면 자동차에 대한 관심이 많다고 분석하여 그 정보를 바탕으로 자동차 관련 용품과 정보를 개인화하여 개인 맞춤 정보를 제공한다. 사물인터넷의 신버전 행동인터넷 최근 빅데이터 분석 분야에서 많이 적용되고 있으며, 우리 일상생활에서 가장 흔히 사용되는 행동인터넷 활용 사례는 바로 웨어러블 기기다. 그중 가장 흔히 사용하는 스마트워치는 심박수, 스트레스 지수, 수면의 질 등 다양한 정보를 파악할 수 있다. 스마트워치를 착용하고 수면을 취하게 되면 수면의 질을 파악하고, 스마트폰 앱과 연동되어 수면 패턴을 분석해준다. 그리고 더욱 질 높은 수면을 취하기 위한 여러 가지 조언을 해주기도 한다. 이처럼 사물인터넷(IoT)과 행동인터넷(IoB)은 디자인 프로세스 관점에서 아날로그 프로세스와 디지털 프로세스의 상호작용과 유사성을 갖고 있다. 즉 서로 다른 형태의 프로세스이지만 상호작용하면서 다양한 분야에서 활용되고 있다. 아날로그 프로세스는 연속적인 값을 다루는 프로세스로, 주로 연속적인 데이터를 처리하고 분석한다. 예를 들어, 아날로그 프로세스는 음향, 영상, 물리량 등의 연속적인 데이터를 처리하는 데 사용된다. 디지털 프로세스는 아날로그 프로세스를 제어하고 모니터링하는 데 사용되며, 아날로그 프로세스는 디지털 프로세스를 통해 데이터를 수집하고 분석하는 데 사용된다. 또한, 행동인터넷은 운전자의 운전 성향, 선호하는 주행 패턴 등 다양한 정보와 수많은 운전자의 개인 데이터와 결합하여 활용될 수 있다. 이 정보를 기반으로 자동차의 성능을 개인화하여 최적화하고 단점은 보완하여 고객 취향에 맞는 자동차를 사용자 경험 디자인(UX-Design) 관점에서 설계할 수 있다. 특히 자동차 안에서의 다양한 제스처 데이터를 수집하여 편리하게 적용시킬 수 있다. 이를테면 전화를 걸고 싶을 때 하는 제스처와 내비게이션 지도를 확대할 때 하는 제스처 등을 분석하여 필요한 상황에 인식하여 서비스를 제공한다. 이러한 방식으로 운전자가 더욱 편리하게, 안전하게 운행할 수 있도록 돕는다. 더 나아가 차량 속도, 운전 거리, 운전 시간 등을 측정하고 운전습관을 분석해 안전운전 여부를 판단해서 이를 보험료 산정에 반영하는 운전습관 연계보험(UBI)도 출시되고 있다. 운전습관 연계보험을 통해 보험사는 사고 위험이 적은 고객을 유치해 손해율을 줄일 수 있고, 운전자는 보험료 할인을 받기 위해 특정 내비게이션 앱이나 운행기록 자기진단 장치를 사용하면서 안전운행을 위해 다방면으로 노력하게 되는 것이다. 운전자와 보험사 양측에 상호작용된 윈윈 상품이 출시되고 있듯이 다른 산업에서도 이를 적용하여 경쟁우위 전략을 새롭게 구상해야 한다. 왜냐하면 그것이 지능화의 출발이기 때문이다. 사물인터넷과 행동인터넷의 관점과 인공지능 전환(Artificial Intelligence Transformation, AX)과 디지털 전환(Digital Transformation, DX)은 서로 다른 개념이지만, 밀접한 관련이 있다. 인공지능·디지털전환 새로운 가치 창출 인공지능 전환은 인공지능 기술을 조직의 전략과 목표에 맞게 적용하여 비즈니스 프로세스, 제품, 서비스 등을 혁신하고 가치를 창출하는 것이다. 인공지능 기술을 활용하여 데이터를 분석하고 예측하여, 자동화와 개인화를 통해 경쟁력을 강화하는 것이 주요 목표다. 디지털 전환은 조직이 디지털 기술을 활용하여 비즈니스 모델, 프로세스, 고객 경험 등을 혁신하는 것이다. 데이터를 수집하고 분석하여, 디지털 플랫폼을 구축하고 디지털 서비스를 제공하는 것이 주요 목표다. 따라서 인공지능 전환과 디지털 전환은 상호 작용하면서 조직의 경쟁력을 강화할 수 있다. 인공지능 기술을 디지털 전환에 적용하면, 데이터를 더욱 효과적으로 분석하고 예측하여, 비즈니스 프로세스를 최적화하고 개인화된 서비스를 제공할 수 있다.
-
- 작성일 2024-03-13
- 조회수 136
-
- [연구] 박사과정 박진우, SCIE 논문지(Cell Press: Heliyon Journal/Q2) 게재
- 박사과정 박진우 학생(지도교수: 정종필)의 연구(YOLOv5 Based Object Detection in Reel Package X-ray Images of Semiconductor Component)가 Heliyon (Impact Factor: 4.0 (2022))에 게재됐다. https://doi.org/10.1016/j.heliyon.2024.e26532 / https://www.cell.com/heliyon/fulltext/S2405-8440(24)02563-5 논문요약 - The industrial manufacturing landscape is currently shifting toward the incorporation of technologies based on artificial intelligence (AI). This transition includes an evolution toward smart factory infrastructure, with a specific focus on AI-driven strategies in production and quality control. Specifically, AI-empowered computer vision has emerged as a potent tool that offers a departure from extant rule-based systems and provides enhanced operational efficiency at manufacturing sites. As the manufacturing sector embraces this new paradigm, the impetus to integrate AI-integrated manufacturing is evident. Within this framework, one salient application is AI deep learning–facilitated small-object detection, which is poised to have extensive implications for diverse industrial applications. This study describes an optimized iteration of the YOLOv5 model, which is known for its efficacious single-stage object-detection abilities underpinned by PyTorch. Our proposed “improved model” incorporates an additional layer to the model's canonical three-layer architecture, augmenting accuracy and computational expediency. Empirical evaluations using semiconductor X-ray imagery reveal the model's superior performance metrics. Given the intricate specifications of surface-mount technologies, which are characterized by a plethora of micro-scale components, our model makes a seminal contribution to real-time, in-line production assessments. Quantitative analyses show that our improved model attained a mean average precision of 0.622, surpassing YOLOv5's 0.349, and a marked accuracy enhancement of 0.865, which is a significant improvement on YOLOv5's 0.552. These findings bolster the model's robustness and potential applicability, particularly in discerning objects at reel granularities during real-time inferencing.
-
- 작성일 2024-02-23
- 조회수 747
-

- [교수동정] ‘인공지능 전환’이 온다 - 스마트팩토리융합학과 박정수 교수
- 디지털 전환(Digital Transformation·DX)이 산업의 근본적 혁신을 위한 방안 중 하나로 떠오르고 있다. 그리고 DX의 성공을 좌우하는 핵심 키는 인공지능 전환(AI Transformation·AX)에 있다. AI는 게임체인저로서 기존 방식으로 해결할 수 없었던 산업 현장의 각종 문제를 해결하고, 새로운 부가가치를 창출하게 한다. 이미 글로벌 기업들이 자사의 제조 공정·제품·서비스 등에 AI를 적극 활용해 경쟁력을 강화하고 있다. AI 알고리즘으로 비즈니스 기회 창출 나아가 인공지능 알고리즘이 우리 삶 곳곳에 원하든 원하지 않든 파고들고 있으며, 챗GPT라는 ‘초거대 AI’가 등장하여 세계적으로 충격을 주고 있다. 챗GPT 열풍에 따라 전 세계는 이미 AI 기술 패권 전쟁을 시작하였다. 초거대 AI의 데이터 학습에는 기존과 비교할 수 없는 연산량과 고속 데이터 처리 속도가 필수다. 또 매개변수라고 불리는 파라미터(매개변수)는 뇌의 학습과 기억, 연산을 담당하는 인간 뇌의 시냅스(신경세포의 접합부)와 유사한 기능을 수행한다. 시냅스는 우리 두뇌에 있는 신경세포로, 시냅스가 많을수록 더욱 고차원적 사고가 가능하다. 글로벌 기업들은 정교하게 설계된 AI 알고리즘을 통해 비즈니스 기회 창출과 자사의 경쟁력을 강화하고 있다. 기업 자체적으로 알고리즘을 개발하는 방법도 있지만, 최근 다른 테크놀로지 기업이 출시한 AI 엔진과 솔루션을 활용해 미래의 수요, 가격 변화, 소비자의 행동 패턴, 선호의 변화 등을 예측하는 기업도 적지 않다. 과거에는 임직원의 경험 혹은 ‘암묵적 지식(Tacit Knowledge)’에 의존하여 의사결정을 했으나 데이터를 근거로 기업에 최적화된 알고리즘을 활용할 경우, 시장 환경에 보다 민첩하게 대응하고 최적화된 비즈니스 프로세스를 개선할 수 있다. AI 전환은 데이터 분석, 기계학습, 자연어 처리 등 AI의 다양한 기능을 활용하여 기업의 제품과 서비스를 개선하고, 효율성을 높이며, 경쟁 우위를 확보할 수 있다. 뿐만 아니라 최근 데이터 패브릭(Data Fabric)을 활용한 머신러닝과 데이터 분석 소프트웨어는 모든 종류의 메타 데이터를 분석할 수 있어야 하며, 활용되지 않는 데이터에서 인사이트를 도출해 낼 수도 있어야 한다. ‘제조 지능화’가 미래 제조업의 성장기반 그러므로 ‘제조 지능화’는 기술과 기능을 구분하여 수단매체와 목적함수 간의 관계 설정이 매우 중요하다. 제조의 관점은 다양하다. 생산, 판매, 그리고 공급망(SCM)을 관점별로 부분 최적화를 넘어 제조 전체 최적화가 실현되도록 통합하는 네트워크 기술과 기능이 중요하다. 따라서 제조 지능화는 제조업이 인공지능(AI), 사물인터넷(IoT), 빅데이터, 로봇 공학, 클라우드 컴퓨팅 등 첨단 정보 통신 기술을 통합하여 생산성을 높이고, 유연성을 강화하며, 비용을 절감하는 과정이다. 제조 지능화의 수단은 인공지능 전환(AX)이며, 목적은 지속 가능한 성장이다. 나아가 품질 개선의 목적은 AI 기반의 품질 관리 시스템을 통해 불량률을 줄이고, 제품의 품질을 일관되게 유지할 수 있는 ‘품질 지능화’이다. 그러므로 미래 제조업의 성장동력과 혁신의 씨앗은 디지털 전환(DX)을 넘어 인공지능 전환(AX)에서 그 해답을 찾아야 한다.
-
- 작성일 2024-02-13
- 조회수 305
-

- [교수동정] AI혁명 중심엔 '반도체'가 있다 - 스마트팩토리융합학과 박정수 교수
- 디지털 변환(Digital Transformation) 시대를 넘어 모든 산업을 관통하는 핵심은 인공지능(AI)과의 접목과 융합 기술이다. 1980년대 PC(윈도 기반), 2000년대 모바일(스마트폰)에 온 세상이 뒤집혔고 이제 그다음 타석에 AI라는 대체 불가능한 타자가 세계 경제에 지각변동을 몰고오는 중이다. 그 중심에 항상 반도체가 존재한다. 2024년 100주년을 맞은 세계 최대 IT·가전 박람회 CES 2024의 슬로건은 “ALL ON”이었다. 이는 모든 것을 밝히며 열린다는 뜻으로, AI가 모든 곳에 있으며 인류의 문제와 과제를 해결하기 위해 글로벌 기술이 한자리에 모인다는 의미이다. 모든 산업을 지각변동시키는 격동의 진앙에는 AI가 있다. 2023년 문서 생성형 인공지능(챗GPT), 이미지 생성형 인공지능(Mid Journey), 컴퓨터 코딩 생성형 인공지능(Codex)이 불을 지폈다면, 올해는 실시간 피드백을 실현하는 적응형 인공지능(Adaptive AI) 기반 모빌리티, 미래 차, 스마트홈, 디지털 헬스 등 다양한 분야의 제품과 서비스에 AI 기술이 접목되어 뉴노멀 경험과 체험을 증명해 보이고 있다. 미래 차 부품의 선두주자 지멘스는 메타버스를 통해 인간과 AI가 실시간으로 협업하여 산업의 현실 문제를 해결하고 있으며, 퀄컴은 온디바이스 AI의 잠재력을, 인텔은 ‘AI Everywhere’라는 비전을 통해 인공지능의 확장성을 강조하고 있다. 특히 기술 혁신에 소극적이라는 평가를 받아왔던 유통, 화장품, 바이오 산업까지 AI를 혁신씨앗으로 제시한 가운데 인텔은 사용자가 클라우드 없이 AI를 활용할 수 있는 ‘온디바이스 AI’가 모든 곳에 존재하는(AI Everywhere) 비전 실현을 가속화할 것이라고 전망했다. 이처럼 모든 글로벌 선도 기업들은 인공지능 기술과 변화에 초점을 맞추고 있다. 그 중심에 시스템로직((System Logic·비메모리) 반도체가 존재하고 있다. 인공지능 전환(AI Transformation)은 AI를 통해 디지털 전환을 추진하는 시스템 로직 프로세스이다. 과거 정보기술(IT)이 산업과 일상의 영역을 허물었듯, 올해의 영역파괴 메가 트렌드가 모든 영역의 AI 전환(AX)이 될 것이라는 데 반론의 여지가 없다. AI 기술은 기업 운영의 근간을 변화시키는 중요한 요소가 되고 있다. 모든 산업과 기업에서 AI를 응용하면 지속 가능성, 생산성, 접근성, 비용 절감, 품질고도화, 고객 만족도 향상 등 다양한 혜택을 누릴 수 있다. 인공지능(AI)은 빅데이터 처리 속도를 높이고 정확도를 높여 복잡한 문제 해결 능력을 갖추고 있어 기업은 새로운 비즈니스 기회를 포착할 수 있다. 더 나아가 비즈니스에서 AI의 역할은 단순히 효율성을 향상시킬 뿐만 아니라 혁신의 원천이 될 수 있다. AI가 제공하는 통찰력은 시장 동향을 읽고 고객의 요구를 깊이 이해하는 데 도움을 준다. 이를 통해 기업은 더욱 전략적인 의사결정을 가능하게 하고 지속 가능한 경쟁 우위를 확보할 수 있을 것이다. 그 중심에는 시스템로직 반도체 기반 애플리케이션이 존재한다. 예를 들어 온디바이스 인공지능(On Device AI) 애플리케이션을 로컬로 실행하는 데는 큰 이점이 4가지 있다. 우선 개인정보, 재무정보, 의료정보를 포함한 모든 정보는 디바이스 외부가 아닌 내부에서 저장 및 처리된다. 둘째, 위치 정보와 사용자의 취향과 활동을 활용하여 더욱 개인적인 AI 어시스턴트를 만들 수 있게 된다. 셋째, 지연과 처리 시간이 상당히 단축된다. 넷째, 클라우드 컴퓨팅을 개입시킬 필요가 없으므로 데이터센터의 에너지 소비가 크게 줄어들고 환경의 지속 가능성이 향상된다. 또한, 온디바이스 AI가 클라우드 AI에 비해 뛰어난 점은 뭐니 뭐니 해도 실시간성이다. 예를 들어 단시간 처리가 필요할 때 시간이 걸리는 인터넷 통신을 사용할 필요가 없다. 따라서 온디바이스 AI는 기업이 생산성 향상과 업무효율을 위해 자체적으로 사용하는 AI를 제품과 서비스로 확장하는 전환점이 될 것이다. 온디바이스 AI는 클라우드 연결 없이 기기 자체에 생성형 AI 기능을 탑재할 수 있어서 일상에도 AI가 스며드는 인공지능 전환(AI Transformation·AX) 시대의 도래를 의미한다. 저성장 초고령화 국면에 진입한 우리 경제의 미래 성장동력은 AX에서 찾아야 한다. 우리가 강점을 지닌 제조업에서 제조현장의 아날로그 기술과 제조 빅데이터 관리기술을 접목하고 융합해서 지능화 시대를 선도할 수 있는 지속 가능한 미래 성장동력을 구동해야 한다. 이는 AI 기술이 혁신의 씨앗이기 때문이다. 그 중심에 AI 기반 스마트 팩토리(제조 지능화)가 존재한다. 그 해답은 AXfactory(AI Transformation Factory)다. 이는 대한민국의 미래 브랜드가 될 것이다.
-
- 작성일 2024-01-17
- 조회수 554
-

- [일반] 2024 "스마트팩토리 데이터 활용 및 분석 실습" 교육 신청
- 2024년도 1월에 가족회사 재직자분들을 대상으로 "스마트팩토리 데이터 활용 및 분석 실습"교육을 진행합니다. 강의와 실습을 통해 제조 데이터를 활용하는 방법을 공유하여 실무에 도움을 주기 위한 재직자 교육입니다. 교육은 1.23(화)-1차 / 1.30(화)-2차로 진행할 예정이며, 교육의 연속성을 위하여 1,2주 차 모두 참여해 주시면 감사하겠습니다. (※개인노트북 필요) 신청방법은 https://forms.gle/Hp3QLZpZyuSiG7G46또는 하단·붙임파일의 포스터 QR코드를 이용하여 구글폼 작성해 주시길 바랍니다. (제출기한: ~1월 17일(수) 오후 4시까지)
-
- 작성일 2024-01-08
- 조회수 1473
-

- [연구] 박사과정 박진우, SCIE 논문지(Journal of King Saud University - Computer and Information Sciences/Q1) 게재
- 박사과정 박진우 학생(지도교수: 정종필)의 연구(LyFormer based object detection in reel package X-ray images of semiconductor component)가 Journal of King Saud University - Computer and Information Sciences (Impact Factor: 6.9 (2022); CiteScore: 6.9)에 게재됐다. https://www.sciencedirect.com/science/article/pii/S1319157823004135 / https://doi.org/10.1016/j.jksuci.2023.101859 논문요약 - With the development of artificial intelligence (AI) technology, companies are rationalizing the facilities required at the production site to suit smart factory plants, and applying AI to the production and inspection processes. In terms of manufacturing production, AI-computer vision can replace existing rule-based systems and can add competitiveness to industrial sites. In order to respond to the innovative business management paradigm in the manufacturing industry, the advancement of smart factory construction in the domestic manufacturing industry is in progress. Accordingly, the introduction of manufacturing execution systems (MES) that apply AI to industrial sites is becoming important. In the context of manufacturing lines that operate under surface mount technology (SMT), the precise quantification of electronic components is crucial for on-time supply chain management and effective production output. However, small-to-medium enterprises often grapple with the lack of sophisticated systems for accurate part counting. Traditional X-ray machines operate on rule-based algorithms, engendering discrepancies in component numbers and engendering inefficiencies. Small object detection using AI deep learning is a useful technology in the production field and can be applied to various fields in the future. YOLOv5 is a fast, high-performance, one-stage object detection program. It uses pytorch, which is lighter than existing models and can be accessed easily by users. To better recognize small objects, we proposed the LyFormer model (LCTC, YOLO, Transformer), which added 1 layer to the existing YOLOv5 network, added 1Head, inserted a transformer module, and preprocessed the data with label normalization, correlation, local texture, and context feature maps. The proposed model is an improved model with better accuracy and speed than the existing YOLOv5 model. We took X-ray images of semiconductor parts, trained using the improved proposed model, and obtained excellent performance. It can be applied to the inspection process in the surface mount technology industry with many small devices in conjunction with production for the advancement of MES. The mAP performance of the improved proposal model was 0.672 compared to 0.399 of the YOLOv5 model, which was a significant improvement. The accuracy of the improved model was 0.915, which was a significant improvement compared to the result of the YOLOv5 model (0.602), and it could be applied directly in the field for object inference, as it could detect objects in reel units.
-
- 작성일 2023-12-28
- 조회수 1597
-

- [교수동정] '구인난 해결사'로봇... 3분 카레도, 변압기도 척척 만들어 - 스마트팩토리융합학과 박정수 교수
- 지난 7일 울산광역시 동구에 있는 HD현대일렉트릭의 변압기 공장. 두꺼운 철문을 열고 공장 안으로 들어서자 로봇 팔처럼 생긴 ‘핸들러’(Handler·철판을 흡착하고 이동시켜 쌓아 올리는 기계 팔)가 5초 간격으로 움직이며 사다리꼴 모양의 전기강판(실리콘 스틸)을 차곡차곡 쌓고 있었다. 이 회사 양재철 HD현대일렉트릭 상무는 “변압기 생산공정 중 첫 단계인 철심 구조물을 만드는 중”이라고 소개했다. 철심 하나의 두께는 불과 0.23~0.3㎜에 불과하다. 이를 적게는 2000장, 최대 1만장까지 오차 없이 쌓아 올려야 한다. 시트 적층을 위해선 그동안 4~6명의 작업자가 일일이 철심을 쌓아야 했다. 자동화 설비를 도입한 이후엔 필요 인력이 1.5명으로 줄었다. 강진호 변압생산부 책임은 “사람이 하면 밤낮으로 일주일 걸리는 작업시간을 나흘 정도로 줄였다”고 설명했다. 산업 현장 곳곳에 로봇이 도입되면서 생산성 향상과 인력난 해소라는 두 마리 토끼를 잡았다는 평가가 나온다. 특히 일손 부족에 시달리고 있는 지방과 제조업 분야를 중심으로 ‘로봇 채용’ 움직임이 활발하다. 요컨대 ‘구인난 해결사’인 셈이다. 한국로봇산업진흥원이 최근 3년간 선도 사업을 통해 자동차·전기전자·섬유 등 업종의 352개사에 로봇 716대를 투입했더니 생산성은 60.4% 향상되고, 불량률은 58.7% 감소했다. 김수영 호서대 스마트팩토리기술경영학과 교수는 “스마트팩토리를 구축하면 생산성을 20~70% 높일 수 있다”고 말했다. 김영옥 기자 시장도 커지고 있다. 14일 한국산업기술진흥원에 따르면 글로벌 로봇 시장 규모는 2021년 332억 달러(약 44조1000억원)에서 2026년 741억 달러(약 98조5000억원)로 연평균 17.4% 성장할 전망이다. 충청북도 음성에 있는 오뚜기 대풍공장도 로봇과 인공지능(AI)을 활용해 생산 효율을 높인 대표적인 현장이다. 이곳에선 국내 시장점유율 1위인 케첩·마요네즈·카레 등을 포함해 452개 품목을 연간 25만t 규모로 생산한다. 지난해에만 8641억원어치를 생산했고, 올해는 여기서 10%가량 늘어날 것으로 예상한다. 지난 8일 현장을 찾아보니 다양한 로봇이 ‘3분 카레’ ‘3분 짜장’ 같은 이 회사의 대표 제품을 쉴새 없이 만들어내고 있었다. 김혁 대풍공장장은 “과거 케첩이나 마요네즈를 한 번에 여러 개 잡아 박스에 넣는 ‘달인’ 같은 작업자가 있었다면 지금은 로봇이 그 역할을 맡고 있다”며 “한때 60여 명이 일하던 케첩 공정에 이제는 절반 정도만 배치했다”고 말했다. 외식 업계도 서빙·조리 등 서비스용 로봇 도입을 확대하고 있다. 교촌에프앤비는 두산로보틱스와 ‘치킨로봇 솔루션 확산’ 업무협약을 맺고 매장 효율화에 나섰다. 시간당 최대 24마리의 닭을 튀길 수 있어 생산성이 높고, 기름 교체와 바닥 청소가 쉽다는 장점이 있다. 롯데리아를 운영하는 롯데GRS는 내년 1월부터 주방 자동화 로봇 ‘알파그릴’을 순차 도입할 계획이다. 이 회사 관계자는 “이에 따라 패티 조리 시간이 5분에서 1분50초로 줄어든다. 단순 작업을 축소해 구인난 해결에 효과가 있을 것”이라고 기대했다. 박정수 성균관대 스마트팩토리융합학과 교수는 “당장 로봇이 단순·반복 업무를 맡은 인력을 줄이는 효과는 있겠지만 장기적으로 고급 인력은 더 많이 고용해야 한다”며 “섬세한 아날로그 기술 구현을 통해 제조업의 본원 경쟁력을 키워야 한다”고 말했다.
-
- 작성일 2023-11-28
- 조회수 989
-

- [학생실적] 스마트팩토리융합학과 ‘IIBC 2023 국내학술대회’ 수상
- 『스마트팩토리융합학과 ‘IIBC 2023 국내학술대회’ 수상』 스마트팩토리융합학과의 연구원들이 한국인터넷방송통신학회가 지난 11월 16일(목)부터 3일간 개최한 ‘IIBC 2023 국내학술대회’에서 눈부신 성과를 이루었다고 전했다. 이번 대회에서 해당 학과 소속 김태용 및 이지은 연구원이 우수 논문상 수상자로 선정되었다. 김태용 연구원은 ‘AI Machine Vision을 활용한 Film 불량 분류 시스템 설계’에 대해 발표했고, 이지은 연구원은 ‘현장 작업자의 안전사고 예방을 위한 눈 피로감 분석 시스템’에 대해 발표했다. 두 연구는 산업 현장의 품질 관리와 작업자 안전에 중점을 둔 혁신적인 연구로 평가받았다. 또한 공석현 연구원은 ‘설비 모니터링을 위한 센서 데이터 기반의 대용량 데이터 수집 및 처리 시스템 설계’를 통해 산업 현장의 효율성을 극대화하는 새로운 방안을 제시했다. 이대희 연구원의 ‘1D-CNN LSTM 기반의 회전기계 고장 진단 기법’은 기계 학습과 인공지능을 결합하여 기계 고장 예측의 정확성을 향상하는 데 기여했다. 김남지 연구원의 ‘딥러닝 기반 작업자 안전을 위한 인간 활동 인식 방법론’과 박지완 연구원의 ‘고차원 데이터의 효율적인 분석을 위한 밀도 기반의 노이즈 제거 및 클러스터링 기법’ 또한 데이터 과학과 인공지능의 융합을 통한 새로운 접근법을 선보였다는 평이다. 학과 관계자는 “학과의 연구 활동들이 미래 산업의 발전에 중요한 토대가 될 것으로 기대된다”며 “이번 학술대회는 스마트팩토리융합학과의 연구원들이 기술 혁신과 산업 안전을 위한 다양한 방안을 제시하는 중요한 자리였다”고 말했다.
-
- 작성일 2023-11-22
- 조회수 1852